

Are You A Cat?
An MLOps Pipeline to Answer the Important Questions
Sometimes it is hard to know if you are a cat or not. The goal of this project is to use deep learning to help with that.
J/K. It’s really about me practicing some MLOps and deep learning stuff. There’s a lot more I want to do to improve this pipeline, so my plans for future iterations are included in the project description below.
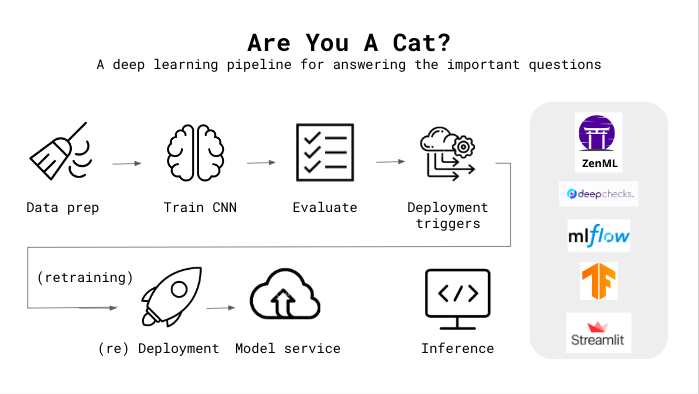
This project uses ZenML to build a simple end-to-end pipeline for a model to identify if a photo (selfie) uploaded to a Streamlit app is of a cat or not. The Github repo for the project is here.
Training Pipeline
The training pipeline is pretty simple: Clean the data, train the model, and evaluate model performance on the test set.
Data
Training data for this project comes from the following datasets:
I’m using a random sample from each of the above. For training, I used 25% cat images, 25% dogs, 25% selfies, and 25% misc.
Data prep is simple: The images are reshaped and normalized. That’s it for now!
Data Validation
Data validation for the training and testing data is done with Deep Checks. There is not currently a ZenML integration for non-tabular data, so this step is not integrated into the pipeline, but can be run ad-hoc via run_data_validation.py. The validation report is saved to the data/ directory.
Model
The model for this project is a 2D CNN, implemented with Tensorflow Keras. The model, hyperparameters, and training metrics are saved using MLflow autologging as experiment tracking artifacts.
The model’s hyperparameters were tuned using keras_tuner. The best model configuration achieves recall of 0.8 and precision of 0.53 on a hold-out test set. Note that there are several limitations to the current model training, which are noted below, so the performance can certainly be improved on (I haven’t done much with the model itself yet).
Evaluation
The trained model predicts on a hold-out validation set, and logs those metrics to MLflow as well.
Deployment Pipeline
The deployment pipeline extends the training pipeline and implements a continuous deployment workflow. It preps the input data, trains a model, and (re)deploys the prediction server that serves the model, if the model’s performance meets some evaluation criteria (minimum recall and precision).
Deployment Trigger
After the model is trained and evaluated, the deployment trigger step checks whether the newly-trained model meets the criteria set for deployment.
Model Deployer
This step deploys the model as a service using MLflow (if deployment criteria are met).
The MLflow deployment server runs locally as a daemon process that will continue to run in the background after the example execution is complete. When a new pipeline is run which produces a model that passes the evaluation checks, the pipeline automatically updates the currently-running MLflow deployment server to serve the new model instead of the old one.
Inference Pipeline
This project primarily uses a Streamlit application for inference, but it contains a separate inference pipeline for testing as well.
Streamlit Application
For inference, I have a simple Streamlit application that consumes the latest model service asynchronously from the pipeline logic.
The Streamlit app takes in a photo (selfie), and returns the probability that you are a cat. It saves the photo and user feedback about the quality of the prediction to S3 for future training and drift detection.
As a next step, I’d like to add a SHAP explanation of why the prediction was made for this particular photo.
Note that there are currently dependency resolution issues using the latest version of ZenML with Streamlit (see this open PR), so the app is temporarily using the model from the training pipeline.
Limitations
This pipeline is a simple first pass, and has some major limitations. Some things I plan to incorporate in the future include:
- Data:
- I didn’t check the accuracy of the labels. I have so far assumed that all the images in the “cats” dataset I downloaded are actually cats, for example.
- I also didn’t confirm that there are no duplicates in the train data and test data (I just split naively and assumed).
- Data validation is not yet incorporated into the training or deployment pipelines, but rather is run ad-hoc separately.
- Model/Training:
- Currently, I’m training locally on a small dataset. In the future, training should be done in the cloud (i.e. Sagemaker) with more data/maybe for longer. I have this mostly set up, but just haven’t completed it yet.
- Hyperparameter tuning is ad-hoc and manual. ZenML is planning hyperparameter tuning support in the future, so I’ll add that once it’s available.
- I haven’t done any in-depth model performance work yet (e.g. no error analysis or real experimentation). I haven’t even tuned the classification cut-off.
- Model training is slow. This may be because I’m using an old laptop at the moment, but there may be ways to improve the efficiency of model training.
- There is no model validation yet.
- Deployment:
- Deployment is currently happening locally via MLflow. In the future I will migrate this to Seldon or KServe for deployment in a more production-friendly setting.
- Monitoring:
- I have very little set up besides basic logs.
- So far I have set up the Streamlit app to save user photos and feedback, which could be used in the future to evaluate model performance on real-world data, catch drift, etc.
- However, I have no input data validation set up, people could give inaccurate feedback, and I haven’t done any rigorous testing on the app UI.
- I’m also not sure if there are privacy concerns with my current approach…
- I have no way to know about user errors in the app, or performance metrics (e.g. latency).
- Orchestration:
- Running the pipeline is currently ad-hoc and manual. In the future I would like to re-train with some of the new, user-generated images on a regular basis with Airflow.
- It would be even cooler if I could do some kind of continual learning approach so that I don’t need to store the images at all…
- Running the pipeline is currently ad-hoc and manual. In the future I would like to re-train with some of the new, user-generated images on a regular basis with Airflow.
- Misc:
- Dockerizing might make sense.
- There are likely opportunities for better testing, since currently the tests I have are quite minimal.