
Some Fancier SQL Stuff

What I Learned: A bit about parititioning, indexing, transactions, window functions, UDFs, and pivoting.
Just working through the SQL things on my “List of Stuff to Learn” today!
Partitioning: Horizontal vs. Vertical vs. Sharding
Partitioning just refers to dividing data up within a database. It’s usually done to improve performance, data availability, or manageability.
Data can be partitioned horizontally or vertically. Horizontally means that a table is split by row - for example, all the students whose names start before M go in table A, and the rest in table B. Sharding is the same thing, except that data are potentially stored across multiple servers.
With vertical partitioning, all the relevant rows stay on the same table, but columns are broken up and stored on additional tables that can be accessed with joins. For example, we may store student names and grades in one table, and contact information in a second table.
Indexing
Indexing is a way to speed up querying by creating pointers to where data are stored within a database. For example, if we wanted to find customers with the last name “Williams” in a large table, this query could be quite slow as the computer needs to look through each row until it finds them. Indexes speed this up by holding a pointer from a sorted record to their corresponding record in the original table where the data actually live.
Basic syntax:
CREATE INDEX col_idx
ON table_name(col) ;
Databases can have more than one index, and each index can be composed of more than one column. Note that indexes take up storage space, and may make writes slower (e.g. INSERTs, DELETEs).
There are two types of database indexes, clustered and non-clustered. I plan to look more into the nuances of how they differ and when to use each option in the future.
Transactions
A transaction is a single unit of logical work made up of one or more operations. Transactions are atomic, meaning that all the operations must succeed, or fail as one unit. For example, when transferring money from one bank account to another, two operations - debiting money from account A and crediting to account B - must both take place so that the accounts are consistent.
Transactions have four standard properties following the acronym ACID:
- Atomic: As stated above, atomicity ensures that all operations within a transaction are completed successfully. If not, the transaction is aborted and rolled back to the former state.
- Consistent: Operations must conform to the existing constraints in the database.
- Isolated: The transaction should not affect other transactions.
- Durable: The result of a transaction must be written to persistent storage. Transaction logs are maintained so that the database can be restored to its original state in case of a failure.
As alluded to, transactions allow for committed changes to be rolled back to a previous state.
In MySQL, the basic syntax is:
START TRANSACTION;
-- do something
COMMIT; -- to save changes
ROLLBACK; -- to roll back the current transaction and cancel changes
By default, MySQL automatically commits the changes permanently to the database (whether in a transaction or not). To execute a multi-line transaction, first turn off autocommit:
SET AUTOCOMMIT = 0;
--or
SET AUTOCOMMIT = OFF;
Window functions
Aggregate functions operate on an entire table and return either a single value, or a value per group if used with a GROUP BY clause. They reduce the number of total rows in a table.
A window function allows a user to aggregate by “group” while each row maintains their original separate identities: the aggregated value is simply added to each row.
Window functions are defined using the OVER() clause. By default, the OVER() clause operates on each row individually. The PARTITION BY argument can be added to subdivide the window into partitions (basically, groups). The ORDER BY clause orders the rows within a partition by their original unique value.
Here’s an example from the Apache Drill docs:
SELECT
dealer_id,
sales,
emp_name,
row_number() OVER (PARTITION BY dealer_id ORDER BY sales) AS `row`,
AVG(sales) OVER (PARTITION BY dealer_id) AS avgsales
FROM q1_sales;
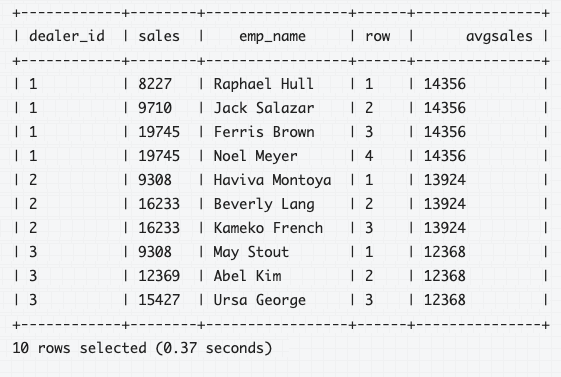
In this example, dealer_id, sales, and emp_name were selected normally. The row_number() argument added a unique row id number per partition and sale, in this case creating a row number that begins at 1 for each dealer id and increases as the sales increase. Finally, avgsales is the average sales per partition (dealer_id), and is the same for all rows in that partition.
Window functions can use all the normal aggregate functions (SUM, COUNT, etc.), as well as things like RANK, LAG, and percentiles. They cannot be combined with standard aggregate functions in the same query, though - meaning they cannot be used in a GROUP BY clause.
User-Defined Functions (UDFs)
Thanks to this tutorial for the basics here! Syntax:
DELIMITER $$ -- reminder: this changes delim so ; doesn’t execute each line
CREATE FUNCTION function_name(input_var type, input_var2 type)
RETURNS data_type_returned
BEGIN -- begins function definition
DECLARE variable_returned type;
SET variable_returned = input_var + input_var2 -- actual function
RETURN variable_returned;
END$$
DELIMITER ;
The function defined above can be used as follows:
SELECT *, function_name(input_var, input_var2) AS variable_returned
FROM table;
Note that saved functions do not alter the tables themselves, but rather just allow you to view impermanent data. Their output needs to be stored to be worked with further.
It may be useful to create a stored procedure to run a function with the input variables all at once:
DELIMITER $$
CREATE PROCEDURE use_function()
BEGIN
SELECT *, function_name(input_var, input_var2) AS variable_returned
FROM table;
END$$
DELIMITER ;
-- which can be used as so:
CALL use_function;
As a more complicated example, this StackOverflow comment has a neat example showing a string-split UDF, which is useful as this is something I often need to do and is not a feature in MySQL:
DELIMITER $$
CREATE FUNCTION SPLIT_STR(
x VARCHAR(255),
delim VARCHAR(12),
pos INT
)
RETURNS VARCHAR(255) DETERMINISTIC -- default is NOT DETERMINISTIC
BEGIN
RETURN REPLACE(SUBSTRING(SUBSTRING_INDEX(x, delim, pos),
LENGTH(SUBSTRING_INDEX(x, delim, pos -1)) + 1),
delim, '');
END$$
DELIMITER ;
-- used like so:
SELECT
SPLIT_STR(membername, ' ', 1) as memberfirst,
SPLIT_STR(membername, ' ', 2) as memberlast
FROM users;
Pivoting
Strangely, MySQL does not seem to have a PIVOT() function. There’s a funky work around using CASE and an aggregate function, which I’ll cover in a moment. For now, here’s how to accomplish a pivot in SQL Server:
SELECT
<columns>
FROM
(
<source query>
)
PIVOT
(
<aggregate function>(<col_to_aggregate)
FOR <spreading_column> IN (<new_spread_elements>)
)
-- for example:
SELECT
customer_id,
jan,
feb,
mar
FROM
(
SELECT
customer_id,
month,
sales_amount
FROM sales
)
PIVOT
(
SUM(sales_amount)
FOR month IN (jan, feb, mar)
)
Pretty straight forward. Now, to accomplish the same thing in MySQL, we would do something like this:
SELECT
sales.customer_id,
SUM(CASE WHEN sales.month = "jan" THEN sales.sales_amount END) "jan",
SUM(CASE WHEN sales.month = "feb" THEN sales.sales_amount END) "feb",
SUM(CASE WHEN sales.month = "mar" THEN sales.sales_amount END) "mar"
FROM
sales
GROUP BY
sales.customer_id;
I suppose this is shorter, but it isn’t as intuitive for me. I’ll need to work with this more to really get a feel for it.
Practicing
It can never hurt to practice more. Here are some resources I’ll be working through daily: